


קובץ רובוטס הוא הכלי שבו נשתמש על מנת למנוע מהזחלן (של גוגל) גישה לספריות או קבצים מסוימים היושבים על השרת שלנו. כאשר מנוע החיפוש מבצע סריקה של אתר, הוא מתחיל את התהליך בקובץ רובוטס שיצרתם עבורו. האלגוריתם "קורא" את ההנחיות שהגדרתם וכך יודע לאן הוא יכול ולא יכול לגשת. יש רק לציין כי אם אין לכם בעיה לחשוף את כל הדפים, התיקיות והקבצים, הרי שאין גם חובה שתגדירו קובץ רובוטס.
שימו לב, זה שאסרנו גישה לדף מסוים, עדיין לא מונע בהכרח מגוגל לאנדקס אותו. תוכלו לקרוא בהרחבה בנושא במדריך שלנו על אינדוקס וסריקה.
כיצד נראה הקובץ?
להלן מרכיבי הפקודה:
- User-agent – השורה הראשונה מגדירה את זהות מנוע החיפוש. באפשרותנו למשל לייחס את הפקודה לבינג, לגוגל וכיו"ב. אם נרצה לייחס אותה לגוגל בלבד, נציין זאת כך – User-agent: googlebot. לעומת זאת אם ברצוננו לא להפלות אלא לייחס את הפקודה לכל מנועי החיפוש באשר הם, נגדיר זאת כך – User-agent: *.
- Allow – אם נחליט שברצוננו לאפשר לזחלן גישה לכל הדפים, כל שעלינו לעשות זה לכתוב בשורה הבאה – Allow: /.
- Disallow – לעומת זאת יתכן שנרצה גם נרצה לחסום תיקיות, דפים או אזורים כאלו ואחרים. אם לדוגמה נרצה לחסום את אזור הניהול של האתר, אז כל הדפים שיופיעו אחרי ה-Admin יהיו חסומים ללא יוצא מן הכלל. כלומר אין צורך לחסום כל דף בנפרד כיוון שהתיקייה עצמה נחסמה. חשוב רק לזכור שכל אזור או תיקייה שברצוננו לחסום, חייבים להיות מופרדים בפקודה חדשה ובשורה חדשה.
- Sitemap – כיוון שברצוננו להקל על הזחלן לראות את דפי האתר ולנווט ביניהם בחופשיות, עלינו להוסיף לקובץ רובוטס קישור גם למפת האתר. ואם לאתר יש יותר ממפת אתר אחת, יש להוסיף את כולן. הפקודה הזו נראית כך – sitemap: http//URL of your website/sitemap_index.xml.
קובץ רובוטס לדוגמה:
כיצד כל זה משפיע על קידום האתר?
ישנם מספר מצבים שבהם לקובץ רובוטס ישנה משמעות מבחינת קידום אתרים. כך לדוגמה אם חברה לקידום אתרים מעבירה את הלקוח לאתר חדש, היא לרוב תפעל על סאב דומיין בסביבת טסט על מנת שלא לחשוף אותו לגולשים. הבעיה היא שאם מתקיימת זהות מוחלטת בין תוכן האתר החדש לאתר הנוכחי, נקבל בסופו של דבר תוכן משוכפל. במצב זה אנחנו מסתכנים כמובן בפגיעה בדירוגים.
לאור זאת, כל שעלינו לעשות זה להגדיר בקובץ רובוטס של האתר שנמצא בבנייה שאנחנו לא מעוניינים שגוגל תאנדקס אותו. מובן רק שחשוב לזכור כי עלינו לשנות בקובץ רובוטס את ההגדרה ברגע שנכניס את האתר החדש לפעולה. מצב נוסף לדוגמה הוא זה שבו ברצוננו פשוט למנוע מגוגל לאנדקס תוכן ספציפי באתר שלנו. הסיבה יכולה להיות תוכן משוכפל או תוכן דל ולא איכותי. למעשה כל תוכן שגילינו שיש בו כדי לפגוע בדירוג שלנו, ניתן לחסימה בקלות על ידי הוספתו לקובץ רובוטס.
ניתן לערוך את קובץ רובוטס ישירות מהשרת או באמצעות תוסף YOAST (למי שיש אתר וורדפרס)
הנה סרטון קצר על התקנת תוסף יוסט:
בנוסף, מומלץ להכיר את הכלי למנהלי אתרים – Search console – שם תוכלו לבדוק את תקינות קובץ הרובוטס שלכם ולראות עבור כל דף באתר שלכם – האם יש איזושהי חסימה עליו בקובץ רובוטס.
פתוח לכל אחד
מטבע הדברים, כשזה מגיע לגוגל, עדיף לשמור על פתיחות באופן כללי. יחד עם זאת, ישנם בכל זאת דפים שלא נרצה לאפשר לגוגל את הגישה אליהם ושנעדיף שלא יופיעו באינדקס. הכוונה היא בין השאר לדפים שיש להקליד סיסמה כדי להיחשף אליהם, דפי Admin וכיו"ב. חשוב להבין כי לכל משתמש ומשתמש יש גישה חופשית לקובץ הרובוטס של האתר אך לא כל משתמש רשאי להכניס בו שינויים. כדי לראות את קובץ הרובוטס של אתר מסוים, עליכם לכתוב את כתובת האתר הראשית ולהוסיף את הסיומת /robots.txt. למשל: hayed.co.il/robots.txt
נסו זאת אפילו כעת!
אנחנו לרוב נוהגים גם לחסום מנועי חיפוש וכלי SEO שסתם יושבים לנו האתר ומעמיסים עליו, למשל מנוע החיפוש YANDEX שמושך חיפושים מאזור רוסיה – לרוב סתם מעמיס על הרוחב פס של השרת ולכן אנחנו חוסמים אותו.
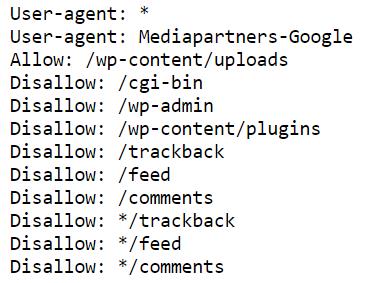
כך נראה קובץ רובוטס ברוב אתרי הוורדפרס שלנו (לפני עידן ה- AI):
User-agent: *
User-agent: Mediapartners-Google
Allow: /wp-content/uploads
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/plugins
Disallow: /trackback
Disallow: /feed
Disallow: /comments
Disallow: */trackback
Disallow: */feed
Disallow: */comments
#yandex-russian spider
User-agent: Yandex
Disallow: /
#ahref
User-agent: AhrefsBot
Disallow: /
#Bing&MSN spider
User-agent: bingbot
Disallow: /
#Baidu spider
User-agent: Baiduspider
Disallow: /
#all other bots
User-agent: Rogerbot
User-agent: Exabot
User-agent: MJ12bot
User-agent: Dotbot
User-agent: Gigabot
User-agent: AhrefsBot
User-agent: BlackWidow
User-agent: Bot\ [EMAIL="[email protected]"]mailto:[email protected][/EMAIL]
User-agent: ChinaClaw
User-agent: Custo
User-agent: DISCo
User-agent: Download\ Demon
User-agent: eCatch
User-agent: EirGrabber
User-agent: EmailSiphon
User-agent: EmailWolf
User-agent: Express\ WebPictures
User-agent: ExtractorPro
User-agent: EyeNetIE
User-agent: FlashGet
User-agent: GetRight
User-agent: GetWeb!
User-agent: Go!Zilla
User-agent: Go-Ahead-Got-It
User-agent: GrabNet
User-agent: Grafula
User-agent: HMView
User-agent: HTTrack
User-agent: Image\ Stripper
User-agent: Image\ Sucker
User-agent: Indy\ Library
User-agent: InterGET
User-agent: Internet\ Ninja
User-agent: JetCar
User-agent: JOC\ Web\ Spider
User-agent: larbin
User-agent: LeechFTP
User-agent: Mass\ Downloader
User-agent: MIDown\ tool
User-agent: Mister\ PiX
User-agent: Navroad
User-agent: NearSite
User-agent: NetAnts
User-agent: NetSpider
User-agent: Net\ Vampire
User-agent: NetZIP
User-agent: Octopus
User-agent: Offline\ Explorer
User-agent: Offline\ Navigator
User-agent: PageGrabber
User-agent: Papa\ Foto
User-agent: pavuk
User-agent: pcBrowser
User-agent: proximic
User-agent: RealDownload
User-agent: ReGet
User-agent: SiteSnagger
User-agent: SmartDownload
User-agent: SuperBot
User-agent: SuperHTTP
User-agent: Surfbot
User-agent: tAkeOut
User-agent: Teleport\ Pro
User-agent: VoidEYE
User-agent: Web\ Image\ Collector
User-agent: Web\ Sucker
User-agent: WebAuto
User-agent: WebCopier
User-agent: WebFetch
User-agent: WebGo\ IS
User-agent: WebLeacher
User-agent: WebReaper
User-agent: WebSauger
User-agent: Website\ eXtractor
User-agent: Website\ Quester
User-agent: WebStripper
User-agent: WebWhacker
User-agent: WebZIP
User-agent: Wget
User-agent: Widow
User-agent: WWWOFFLE
User-agent: Xaldon\ WebSpider
User-agent: Zeus
Disallow: /
חסימות מנועי בינה מלאכותית בקובץ רובוטס
עם כניסת מנועי בינה מלאכותית שסורקים את האתרים שלנו , יש צורך בעדכון קובץ הרובוטס שיאפשר/לא יאפשר (לבחירתכם) סריקה של מידע מהאתר
להלן המלצות ועדכונים לקובץ רובוטס כפי שהומלץ באתר SEL

כאן תוכלו לראות את רשימת כל הבוטים
וזו ההמלצה לעדכון קובץ רובוטס על מנת שיאפשר סריקה וגישה למנועי בינה מלאכותית, אך לא יאפשר להם לאסוף/להתאמן על המידע מהאתר שלכם:

כל ההמלצות להגדרות קובץ רובוטס כולל הנחיות לבינה מלאכותית – בטבלה הבאה
למידע מפורט על הבוטים של GPT שצריך לחסום / לפתוח לסריקה
הנחיות קובץ רובוטס – כולל הגדרות גישה/חסימה למנועי בינה מלאכותית
# הגדרות כלליות לכל הזחלנים (כולל מנועי חיפוש מסורתיים ובוטים כלליים)
User-agent: *
Allow: /
# חסימת אזורים רגישים ופנימיים
Disallow: /admin/ # אזורי ניהול
Disallow: /private/ # תיקיות פרטיות או פיתוח
Disallow: /temp/ # תיקיות זמניות
Disallow: /search/ # תוצאות חיפוש פנימיות (למנוע כפילויות)
Disallow: /*?* # כתובות URL עם פרמטרים (למנוע כפילויות ופילטרים)
Disallow: /wp-admin/ # תיקיית ניהול וורדפרס (אם רלוונטי)
Disallow: /wp-includes/ # תיקיית קבצי ליבה של וורדפרס (אם רלוונטי)
# חסימת בוטים של AI המיועדים לאימון מודלים
# חסימת תוכן מאימון מודלי AI
User-agent: GPTBot # OpenAI (אימון)
Disallow: /
User-agent: ClaudeBot # Anthropic (אימון)
Disallow: /
User-agent: Google-Extended # גוגל (אימון AI ואינדוקס קשור ל-Gemini מעבר לחיפוש רגיל)
Disallow: /
User-agent: CCBot # Commoncrawl (משמש לאימון AI)
Disallow: /
# הרשאת בוטים של AI המיועדים לחיפוש והסקה בזמן אמת
# חיוני לנראות בתשובות AI חיות וציטוטים
(אינדוקס למחקר וקישורים חיים של ChatGPT)
User-agent: OAI-SearchBot # OpenAI
Allow: /
(שליפה על פי דרישה כאשר משתמש משתף קישורים או ChatGPT זקוק לנתונים נוספים)
User-agent: ChatGPT-User # OpenAI
Allow: /
(שליפה בזמן אמת של כתובות URL מצוטטות במהלך שיחות צ'אט של Claude)
User-agent: Claude-User # Anthropic
Allow: /
(זחלן ממוקד לתוכן אינטרנט עדכני, המזין את סוכן הדפדפן של Claude)
User-agent: claude-web # Anthropic
Allow: /
(זחלן ראשי המאנדקס אתרים לבניית מנוע החיפוש של Perplexity AI)
User-agent: PerplexityBot # Perplexity AI
Allow: /
(טוען דף רק כאשר משתמש לוחץ על ציטוט של Perplexity)
User-agent: Perplexity-User # Perplexity AI
Allow: /
(שירות זחילה ברירת מחדל של Bing, מפעיל את Bing Search ו-Bing Chat/Copilot)
User-agent: BingBot # Microsoft
Allow: /
# זחלן חיפוש מסורתי של גוגל (חיוני לאינדוקס חיפוש רגיל)
User-agent: Googlebot
Allow: /
Sitemap: https://yourdomain.com/sitemap.xml
——————————————————————————-
הסברים על קובץ רובוטס ונקודות חשובות:
User-agent: *: זהו הכלל הכללי שחל על כל הזחלנים שלא צוינו במפורש. הוא מאפשר גישה לכל האתר (Allow: /) אך חוסם אזורים נפוצים שאינם מיועדים לאינדוקס ציבורי או שעלולים ליצור כפילויות.-
חסימות בסיסיות:
/admin/,/private/,/temp/,/wp-admin/,/wp-includes/: אלו תיקיות נפוצות המכילות תוכן ניהולי, פיתוח או זמני שאין לאנדקס./*?*: כלל זה חוסם כתובות URL המכילות סימן שאלה, המשמש לרוב לפרמטרים של חיפוש פנימי, סינון או מיון, ועלול ליצור כפילויות תוכן רבות.
-
בוטים של AI לאימון (
Disallow: /): בוטים אלו אוספים נתונים לפיתוח ואימון מודלי AI. חסימתם מונעת שימוש בתוכן שלך למטרות אלו, אם זו העדפתך. -
בוטים של AI לחיפוש/הסקה (
Allow: /): בוטים אלו משמשים לשליפת מידע בזמן אמת כדי לענות על שאילתות משתמשים או להופיע בתוצאות חיפוש מבוססות AI. הרשאתם חיונית לנראות שלך בפלטפורמות AI. -
Googlebotו-BingBot: אלו זחלני החיפוש המסורתיים של גוגל ובינג, החיוניים לאינדוקס רגיל ולהופעה בתוצאות חיפוש קלאסיות, וגם מזינים את יכולות ה-AI של מנועים אלו. -
Sitemap: https://yourdomain.com/sitemap.xml: חשוב לכלול את הנתיב למפת האתר שלך, המסייעת לכל הזחלנים להבין את מבנה האתר ולגלות את כל הדפים החשובים. החלף אתyourdomain.comבשם הדומיין שלך.
הערה חשובה: קובץ robots.txt הוא בקשה לזחלנים, לא מנגנון אכיפה. בוטים "טובים" (כמו אלו של גוגל, OpenAI, Anthropic, Perplexity) בדרך כלל מצייתים לו, אך בוטים זדוניים עלולים להתעלם ממנו. כדי להסתיר תוכן באופן מוחלט, יש להשתמש בתגי מטא noindex או בהגנה באמצעות סיסמה.



